Анатолий Лихницкий
Стерео или моно
Моя система является монофонической.
Сусуму
Сакума
Первым, кто открыто заявил, что
предпочитает моносистемы стереофоническим, стал известный японский самопальщик
Сусуму Сакума [1]. Его хобби - проектирование ламповых усилителей, схемы и
конструкции которых никак не вписываются в традиционную инженерную логику. И,
тем не менее, многие его, казалось бы, абсурдные идеи в последнее время нашли
применение в аппаратуре "хай-энд". Напомню, что Сакума одним из
первых в мире отказался от использования отрицательной обратной связи и
каскадов типа SRPP. Он впервые применил в качестве драйверных каскадов оконечных
усилителей мощные лампы, а также заменил межкаскадные RC-связи на трансформаторные. Сам он
написал об этом так: "Единственный способ добиться энергичности (energy) и основательности
(frame) звучания
- установить много трансформаторов, хотя я не могу дать этому научного
обоснования".
 Сакума с недоверием относится к инженерному
типу мышления, и потому даже не пытается приводить какие-либо технические
аргументы в защиту выбранных им конструкторских решений. На вопрос
"Сакума, для кого ты делаешь усилители?" он всегда отвечает: "Я
делаю усилители для своего собственного удовольствия, как любитель".
Сакума с недоверием относится к инженерному
типу мышления, и потому даже не пытается приводить какие-либо технические
аргументы в защиту выбранных им конструкторских решений. На вопрос
"Сакума, для кого ты делаешь усилители?" он всегда отвечает: "Я
делаю усилители для своего собственного удовольствия, как любитель".
И все же его утверждение, что
монозвучание лучше, чем стереофоническое, нельзя рассматривать как невинное
чудачество любителя аудио. За ним кроется нечто очень серьезное, то,
что, в конце концов, может подорвать идеологию всей индустрии звукозаписи и
мирового производства аудиоаппаратуры hi-fi и high end; а значит, это утверждение несет
даже потенциальную угрозу национальной безопасности экономически развитых стран
Европы, Америки, Азии, и в частности России.[1]
Казалось бы, перед всеобщей угрозой ученые, имеющие отношение к аудио (я имею в
виду и членов AES), должны объединиться и внести в этот вопрос требуемую ясность. Но не
тут-то было. В своих исследованиях они стараются избегать тем, актуальных для
человечества. Наверное, поэтому ответ на вопрос "стерео или моно?" с
научных позиций придется давать мне, такому же, как и Сакума, только
российскому, любителю аудио.
Сначала я со всей тщательностью
повторил неизвестные большинству аудиофилов эксперименты Сакумы по
субъективному сравнению стереофонического и монофонического звучания. В ходе
экспериментов я сравнивал звучание грамзаписей, воспроизведенных через
одноканальную систему (с одним громкоговорителем), с их звучанием через
двухканальную систему (с использованием двух громкоговорителей) по признакам,
приведенным в методике аудиоэкспертизы [2]. В процессе прослушивания
проигрывались грамзаписи, сделанные в период с 1900 по 1963 год через
аудиосистему, описанную в "АМ" № 2 (31) 2000, с. 121-124. При
проигрывании грампластинок на 78 об/мин я использовал головку звукоснимателя
фирмы "Siemens", а для грамзаписей Lp - головку звукоснимателя "Sumiko
Blue Point",
включенную через самодельный ламповый стереофонический предусилитель. В
монофоническом режиме был задействован один канал аудиосистемы, причем при
воспроизведении Lp выходные обмотки головки "Blue Point" были соединены
последовательно. Музыкальным материалом служили записи оркестровых
произведений, выполненные с применением разных микрофонных техник, так как
именно они позволяют наилучшим образом выявить преимущества
"двухушного" слушания музыки перед "одноухим" (более
подробно об этом будет сказано ниже).
Использованные при проведении экспериментов грамзаписи
1. Spain. Chicago SO,
F. Reiner ("RCA Victor", LSC-2230; "Living Stereo")
2.
Saint-Saens. Concerto № 2, A. Rubinstein (piano), Symphony of the Air, A.
Wallenstein ("RCA Victor" LSC-2234; "Living Stereo")
3.
Beethoven. Symphony № 3 in E Flat op. 55 "Eroica", Pittsbufgh SO, W.
Steinberg ("Command classic" CC11019 CD)
4.
Bartok. Concerto for Orchestra, Berlin PO, H. Karajan ("Deutsche
Grammophon" 2535202)
5.
Rimsky-Korsakov. Scheherazade op. 25, New York PO, L. Bernstein
("Columbia" ML 5387)
6.
Schumann. Symphony № 2 in c major op. 61, The Stadium Concerts SO, L. Bernstein
("Music Appreciation Records" MAR 575А)
7.
Beethoven. Symphony № 3 in E Flat op. 55 "Eroica", (4 th Mov.),
London PO, S. Koussevitsky ("Victor" 8673)
8.
Dukas. L’apprenti Sorcier, PSO of New York, A. Toscanini ("Victor",
7021)
9.
Rossini. Guglielmo Tell (Sinfonia), Corpo di Musica, P. Nevi
("Fonotipia" № 62227)
Примечание.
Номера 1 и 2 выполнены с использованием микрофонной техники А-В;
номера 3 и 4 — с использованием
полимикрофонной техники;
остальные грамзаписи монофонические;
грамзапись 9 - акустическая.
Выводы
1. Монофоническое звучание (то есть
через один громкоговоритель) проигрывает стереофоническому по уровню баса[2],
однако выигрывает в части его артикуляции (речь идет о характере
звукоизвлечения).
2. Монофоническое звучание во всех музыкальных
регистрах воспринимается как более ясное; при этом мешающее действие
реверберации в комнате при монозвучании гораздо менее заметно, чем при стерео-.
3. Стереофоническое воспроизведение
воспринимается слушателем как менее энергичное, менее динамичное, а также как
более "мутное".
4. Пространственное впечатление,
прежде всего проработка планов в глубину, при моновоспроизведении более
реалистичное.
5. Целесообразность и связанность
всех элементов звучания при монофоническом воспроизведении воспринимаются как
более отчетливые.
Результаты прослушивания заставили
меня поверить в правильность кажущегося на первый взгляд абсурдным утверждения
Сакумы о преимуществах монофонического звуковоспроизведения перед
стереофоническим, особенно меня удивило, что это преимущество сохраняется при
проигрывании стереозаписей.
Попробую дать психофизическое
обоснование этому явлению. Для начала разберемся, что же такое пространственный
слух. Академическая наука главным предназначением пространственного слуха
считает способность слушателя определять местоположение источника звука в
горизонтальной и вертикальной плоскостях относительно головы слушателя, а также
его удаленность. Это явление называют пространственной
локализацией. Рассмотрим механизм пространственной локализации в
горизонтальной плоскости. Начнем с общеизвестного - с того, что в нем
задействован подсознательный анализ сходства и различия сигналов, формирующихся
в правом и левом ухе. Если сигналы одинаковы, то происходит их слияние и перед
слушателем возникает слуховой образ источника. Если они имеют различия по
времени прихода в правое и левое ухо (в пределах от 0 до 630 мкс) или несколько
отличаются по интенсивности, например из-за экранирующего действия головы
слушателя, то в сознании слушателя эти сигналы также сливаются, однако слуховой
образ воспринимается как смещенный в сторону уха, которое получило опережающий
или более громкий сигнал. Поскольку при формировании ощущения направления на
источник звука мозг оценивает только упомянутые различия ушных сигналов[3], то его нетрудно обмануть, имитируя
такие различия с помощью двух расположенных по разные стороны от слушателя
громкоговорителей. Например, подобрав различия в задержке и уровне сигналов,
воспроизводимых этими громкоговорителями, можно не только создать между ними
несуществующий, так называемый фантомный источник
звука, но также влиять на его расположение в пространстве между
громкоговорителями. Впервые эту возможность подметил А. Блюмляйн в 1931 году.
Из-за огромной значимости пространственного слуха для будущего аудиоиндустрии
ученые, имеющие прагматический склад ума, всерьез занялись исследованием этого
явления. Естественно, что в первую очередь их внимание было сосредоточено на
способности слушателя локализовать источники звука в горизонтальной плоскости,
а также на изысканиях способов обмануть эту способность. И вскоре такие способы
удалось найти.
Было установлено [З], что механизмы
локализации - временной (фазовый),
опирающийся на различия в запаздывании сигналов, и уровневый, учитывающий различия этих сигналов по уровню громкости,
- мозг слушателя использует как бы независимо друг от друга.
Этот тщательно проверенный научный
факт был с восторгом принят в аудиоиндустрии, так как открыл возможность
получать стереоэффект в аудиоаппаратуре, не затрудняя себя копированием
естественных различий ушных сигналов, а создавая лишь их временные или
уровневые различия. В результате, в стереозаписи стали широко применяться
соответствующие микрофонные техники.
К первой группе относят техники,
основанные на использовании различий интенсивности стереосигналов, так
называемая стереофония по интенсивности
(intensivity stereo),
в которых временные (фазовые) различия этих сигналов были полностью
нивелированы. В их число входят системы Блюмляйна, Х/Y, М/S, а также полимикрофонные.
Ко второй группе - техники,
основанные на временных различиях стереосигналов (time based
stereo), почему-то
называемые у нас фазовой стереофонией.
Это, прежде всего система А-В, а также ORTF, SASS и другие. Более подробно о
микрофонных техниках см. в "АМ" № 4 (5) 95, с. 66-73.
Известно, что подавляющее
большинство современных звукозаписей (около 90%) делается с помощью микрофонных
техник интенсивностной стереофонии. Такой крен в звукозаписи многие и сейчас не
считают ошибочным, поскольку для этих в своем роде коммунистов основная задача
пространственного слуха остается прежней - неуклонно, причем с большой
точностью, определять направление на главный источник звука. Конечно, если вы
охотник или, наоборот, вынуждены убегать от злобных хищников, эта задача и
впрямь является для вас жизненно важной. Однако когда вы идете не на охоту, а
на музыкальный концерт, возникает естественный вопрос: какую роль выполняет
пространственный слух в концертном зале? Думаю, что читатель согласится со мной
в том, что расположение музыкальных инструментов на сцене не может быть
жизненно важным для слушателя и что на восприятие музыки, ради которого, как
мне кажется, он пришел на концерт, оно не оказывает решающего влияния. Ведь это
расположение, за редким исключением, выбирается дирижером с тем, чтобы было
проще общаться с музыкантами, а также балансировать громкость звучания
инструментов. Зачем же тогда нужен пространственный слух при слушании музыки?
Оказывается, он необходим для того, чтобы мозг слушателя мог произвести так
называемое бинауральное освобождение от
маскировки [4].
Эту свойственную каждому нормальному
человеку способность демонстрирует известный опыт [5]. Если источник звука S и источник помехи N находятся в горизонтальной плоскости в разных направлениях
относительно слушателя (например, под углом 90°), то порог слышимости при маскировке[4]
полезного звука помехой понижается на 9 дБ по сравнению со случаем, когда эти
источники располагаются в одном направлении относительно головы слушателя.
Последний вариант соответствует общеизвестным данным о маскировке.
Именно благодаря бинауральному
освобождению от маскировки живое звучание рассредоточенного на сцене оркестра
становится ясным и прозрачным, в нем прорисовывается множество деталей,
слушатель может воспринимать каждый инструмент в отдельности, субъективно
отделять прямой звук от реверберации, не обращать внимания на чихание и кашель
в зале и тому подобное. О том, что мы неосознанно прибегаем к такому
освобождению, свидетельствует хотя бы опыт каждого джентльмена вести на
вечеринке интимный разговор с соседкой, не замечая при этом шума, создаваемого
другими участниками встречи. Эта способность получила название эффекта коктейльной вечеринки (cocktail
party - effect) [6]. Кстати, он исчезает, как
только вы затыкаете одно ухо. Советую вам проверить это на себе, сравнив
восприятие музыки в концертном зале при "одноушном" и
"двухушном" слушании.
Для нас же главный вопрос
заключается в том, может ли стереосистема, способная вызвать у слушателей
устойчивую локализацию фантомных источников звука, обеспечить одновременно их
освобождение от маскировки звучанием других источников, находящихся на той же
сцене, но под другим углом к слушателю. Вопрос этот закономерный, так как вовсе
не очевидно [7], что локализация источников звука и бинауральное освобождение
от маскировки обеспечиваются одними и теми же механизмами слуха. Оказывается,
исследованием этого вопроса практически никто не занимался, хотя
психофизическая наука породила одно - впрочем, достаточно убедительное -
предположение, что эффект освобождения достигается в результате текущей кросскорреляционной переработки ушных
сигналов мозгом слушателя [8], [9]. Из теории корреляционных функций известно,
что сигнал можно отделить от помехи, если от полезного источника мы получаем не
один, а пару сигналов, которые когерентны[5] между
собой и отличаются от сигналов-помех относительным
запаздыванием ![]() , иначе говоря - временем отставания одного сигнала в паре от
другого. Такой способ вычленения полезных сигналов был назван кросскорреляционным, или
, иначе говоря - временем отставания одного сигнала в паре от
другого. Такой способ вычленения полезных сигналов был назван кросскорреляционным, или ![]() - индикацией [10].
- индикацией [10].
|
|
|
Рис. 1. Прохождение сигналов от естественных точечных
источников звука до ушей слушателя от полезного S и от помехи N: а) схема прохождения сигналов ( б) временные различия ушных сигналов для случая, когда эти
сигналы – короткие импульсы (где |
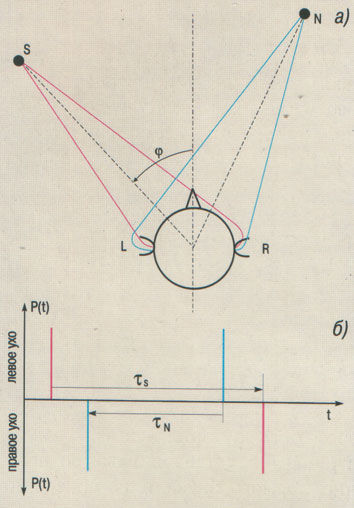
Естественные звуки, которые воспринимает
слушатель, как видно на рис. 1а, несут его мозгу достаточную информацию для
приведения в действие кросскорреляционного способа освобождения полезного
сигнала от помех. На этом рисунке в горизонтальной плоскости изображены два
находящихся в разном направлении относительно головы слушателя источника звука:
S - источник полезного сигнала, и N - источник помехи. От каждого из них
слушатель улавливает по паре сигналов. Понятно, что сигналы в каждой такой паре
имеют между собой большое сходство и поэтому когерентны, тогда как по
относительному запаздыванию они не равны друг другу. Последнее объясняется
характерной для каждого положения источника в пространстве неодинаковостью
расстояния до левого и правого ушей слушателя. Именно различие относительных
запаздываний, обозначаемое мной неравенством ![]() (см. рис. 1б),
имеет решающее значение для кросскорреляционного освобождения сигналов источника
S от маскировки сигналами источника
помех N [11]. Для слуха человека
относительное запаздывание, соответствующее определенному местоположению
источника звука в окружающем пространстве, равно
(см. рис. 1б),
имеет решающее значение для кросскорреляционного освобождения сигналов источника
S от маскировки сигналами источника
помех N [11]. Для слуха человека
относительное запаздывание, соответствующее определенному местоположению
источника звука в окружающем пространстве, равно ![]() (где
(где![]() - максимально возможное различие ушных сигналов по времени,
составляющее 630 мкс;
- максимально возможное различие ушных сигналов по времени,
составляющее 630 мкс;
![]() - угол на горизонтальной плоскости между осью симметрии
головы слушателя и проекцией на нее направления на источник).
- угол на горизонтальной плоскости между осью симметрии
головы слушателя и проекцией на нее направления на источник).
Текущий кросскорреляционный анализ,
осуществляемый, как предполагается, мозгом слушателя, с одной стороны,
объединяет пару когерентных ушных сигналов в один слуховой объект, с другой -
сохраняет в подсознании как пароль информацию об относительном запаздывании.
Последнее вполне естественно, так как аргументом кросскорреляционной функции
является не текущее время, а именно это запаздывание.
Чем больше отличие относительных
запаздываний сигналов, исходящих от источников S и N, тем больше различаются их
кросскорреляционные функции, а значит, тем лучше мозг обособляет полезный
сигнал. Что любопытно, кросскорреляционный способ предоставляет слушателю
возможность отличить сигнал от помехи, даже когда они мало отличаются друг от
друга (например, если и те и другие сигналы - щелчки, как показано на рис. 1б) и звучат одновременно.
Кросскорреляционное разделение слухом сигналов наблюдается, даже когда сигналы
от источника S когерентны, а от источника N некогерентны. Это подтверждается
фактом, что в реальных условиях восприятию прямого звука диффузное поле реверберации
не мешает.
Достоинством корреляционной модели
является то, что она математическая, а значит, все ее возможные, а также
невозможные следствия легко предсказуемы. Например, модель эта, корректно
раскрывает механизм бинаурального освобождения полезного сигнала от маскировки,
но при этом она бессильна объяснить [12], как происходит выделение информации,
необходимой для формирования ощущения направления на источник звука, из
уровневых различий. Но, как говорится, нет худа без добра. На этот раз научное противоречие даже
принесло некоторую пользу, так как подтвердило мою точку зрения относительно
того, что механизмы локализации и бинаурального освобождения от маскировки по
своей сути должны быть совершенно разными.
Если обдумать сказанное, то остается признать, что накопленные наукой и
широко использованные в стереофонии знания о пространственной локализации, а
также все хитрости, придуманные ради того, чтобы обмануть механизмы локализации
для достижения так называемого стереоэффекта, можно спокойно выбросить на
свалку. Резкость моего заявления оказывается оправданной, если считать феномен
бинаурального освобождения главным при двухушном восприятии музыки. Надеюсь,
что хотя бы меломаны меня в этом поддержат.
Попробуем теперь хотя бы качественно
оценить способность обычных стереофонических звукозаписей, выполненных с
применением известных микрофонных техник, и воспроизводящей стереосистемы с
двумя громкоговорителями донести до слушателя не только информацию, необходимую
для правильной локализации источников звука, но и ту, которая гарантирует
проявление феномена бинаурального освобождения. Хотелось бы поверить в
способность аудиоаппаратуры вызывать у слушателей оба названных эффекта. Однако
оказалось, что стереозаписи, выполненные с применением микрофонных техник,
работа которых основана на улавливании только различий в интенсивности
стереосигналов, принципиально не способны донести до слушателя информацию,
необходимую для срабатывания указанного механизма освобождения. Это означает,
что мозг слушателя, который непрерывно высчитывает текущие кросскорреляционные
функции ушных сигналов, при прослушивании таких стереозаписей в результате
действия названного механизма воспримет все источники звука как условно
находящиеся на одной оси в пространстве между громкоговорителями, тогда как
локализоваться на стереосцене они будут в разных направлениях - что само по
себе даже забавно. Этот пример иллюстрирует версию о различии между механизмами
локализации и пространственного освобождения от маскировки. Получается, что
из-за отсутствия временных (фазовых) различий между ушными сигналами
стереозапись, сделанная с использованием микрофонных техник интенсивной
стереофонии, в принципе не может звучать более ясно и прозрачно, чем
монофоническая.
|
|
|
Рис. 2. Прохождение сигналов от источников звука S и N до ушей слушателя через
стереосистему, включающую два встроенных в искусственную голову микрофона и
два разнесенных громкоговорителя: а) схема прохождения через стереосистему до ушей слушателя
сигналов от источников S и N; б) временные различия ушных сигналов для случая, когда эти
сигналы – короткие импульсы и попадают в уши слушателя через стереосистему
(где |
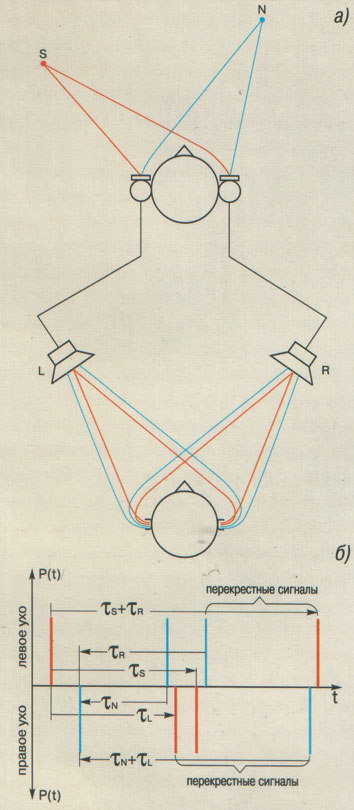
Менее очевидной может показаться
утрата информации, необходимой для бинаурального освобождения в тех случаях,
когда стереозаписи выполнены с использованием микрофонных техник фазовой
стереофонии. Чтобы убедиться в том, что эта утрата все же происходит,
рассмотрим рис. 2а. Здесь изображено
прохождение сигналов от тех же источников S и N к слушателю через стереосистему, то
есть дополнительно через два микрофона, встроенные в искусственную голову, и
затем через два разнесенных громкоговорителя. На первый взгляд, мы имеем
идеальный, "экологически чистый" вариант донесения до слушателя всей
пространственной информации. Но, не будем спешить с выводами и сравним эту
схему со схемой прохождения сигналов от тех же источников в естественных
условиях (рис. 1а). Оказывается, при
прослушивании стереосистемы слушатель улавливает вдвое большее количество ушных
сигналов, чем в естественных условиях. В их числе - пара когерентных сигналов,
сообщающих о местоположении источника полезного сигнала в правом
громкоговорителе, и пара с информацией о местоположении того же источника в
левом громкоговорителе. Аналогичным образом слушатель воспримет пары
когерентных сигналов, оповещающих о местоположении там же двух источников
помех. Конечно, мозг слушателя попытается распознать временные различия в парах
ушных сигналов, соответствующих фантомам полезного источника и источника помех,
но тогда он воспримет их как слабо когерентные. Спутанность ушных сигналов,
соответствующих фантомным источникам звука, хорошо видна на рис. 2б. Плохо то, что она возникает на отрезке
времени, совпадающем с активным воздействием на восприятие первой волны звука.
Из-за этой, как оказалось решающей, неразберихи в сигналах мозг слушателя в
стремлении освободиться от маскировки, как это предписано "моделью
предпочтений Османа" [13], предпочтет фантомным источникам реальные, то
есть правый и левый громкоговорители, хотя в них полезный сигнал и помеха уже
неразделимы. Таким образом, ожидаемый эффект освобождения от маскировки и в
этом случае должен либо отсутствовать совсем, либо быть очень слабым, особенно
если к этому добавить фазовые рассогласования каналов стереосистемы,
возникающие, например, в результате распада поверхности диффузоров
громкоговорителей на независимые зоны излучения.
Даже при беглом ознакомлении с
рисунками бросается в глаза главная причина утраты когерентности ушных
сигналов, соответствующих фантомным источникам - это перекрестные сигналы (то есть сигналы из правого громкоговорителя в
левое ухо, и наоборот). Эти противоестественные сигналы к тому же слегка
опаздывают, примерно на 100 мкс, так как проходят более длинный путь, чем
прямые. Именно из-за добавления этих сигналов мы ощущаем такое разительное
ухудшение пространственного впечатления при стереовоспроизведении по сравнению
со слушанием в естественных условиях. Эту разницу нельзя было не заметить, и
некоторые прогрессивные несоветские ученые заинтересовались влиянием
перекрестных сигналов на пространственное восприятие, в частности, на
когерентность ушных сигналов [14]. Более того, в 1962 году М. Шредеру и Б.
Аталу [15] в лабораторных условиях удалось при воспроизведении через два
разнесенных громкоговорителя исключить перекрестные сигналы, впервые применив
их электрическую компенсацию. Спустя 7 лет П. Дамаске и В. Меллерт [16], а
также Р. Кюрер, Г. Пленге и Г. Вилкенс [17] создали пригодные для промышленного
производства системы, в которых также была применена компенсация перекрестных
сигналов. Через 16 лет в СССР автором статьи с группой сотрудников было
смакетировано устройство для электрической компенсации перекрестных сигналов в
трехмесячный срок. Срок был установлен приказом министра промышленности средств
связи. Об этом достижении было сообщено в газете "Социалистическая
Индустрия" от 25 февраля 1979 года. Но это уже чисто советская история.
Помню, я сделал тогда несколько записей оркестра с балкона в Большом зале
Ленинградской филармонии с помощью двух микрофонов, встроенных в искусственную
голову. Эти записи, воспроизведенные через обычную стереосистему и устройство
для компенсации перекрестных сигналов, звучали, несмотря на грубое нарушение музыкального (инструментального) баланса, поразительно ясно, но тогда
всех, и присутствовавшего журналиста из газеты, взволновала удивительная
локализация источников звука. Особый восторг вызвала демонстрация специальной записи
того, как мотоциклист разъезжает вокруг слушателя.
Именно тогда аудиотехника имела шанс
пойти по пути улучшенной стереофонии (названной бинауральной[6]), но, по-видимому, всемирная
звукорежиссерская мафия каким-то образом воспрепятствовала этому[7].
Одержав победу над здравым смыслом,
звукорежиссеры не стали задумываться о вреде перекрестных сигналов. Осуществляя
стереозаписи, они пошли по пути искусственного конструирования стереосцены, а также добивались ясного звучания с
помощью звукорежиссерского пульта. Именно он дал возможность балансировать
громкость звучания музыкальных инструментов, устанавливать соотношение прямого
звука и реверберации, выбирать ее параметры и т. п. Понятно, что в этой работе
без полимикрофонной техники и искусственной реверберации было уже не обойтись.
Поскольку первичного звукового пространства в стереозаписях совсем не
оставалось, чисто конструкторская работа звукорежиссера, называемая сведением, была признана творческой и
попала под защиту Закона "Об авторском праве и смежных правах".
Стоит ли упрекать звукорежиссеров за
самозащиту? Ведь если бы в стереозвучании был задействован феномен
бинаурального освобождения от маскировки, то их работа по сведению стала бы
никому не нужна. Достаточно вспомнить, что на музыкальном концерте слушатель не
испытывает больших неудобств от плохого музыкального баланса или от
неоптимального соотношения прямого звука и реверберации. Однако если бы он не
обладал способностью бинаурального освобождения, скажем, имел бы только одно
ухо, то для того, чтобы выбрать себе подходящее место в концертном зале, ему
пришлось бы нанимать специалиста по рассаживанию слушателей, например проф. В.
Рейхардта.
Тут, я думаю, настал момент вывести
на сцену оппонирующего мне аудиофила: "То, к чему вы склоняете нас, совсем
не «внушает»! Ну не удалось достичь непонятного широкой публике эффекта, и что?
Стереофоническая пластинка от этого хуже монофонической не стала! Зато как
интересно из своей каморки наблюдать за гигантской стереосценой".
При всей привлекательности наблюдений
из каморки хочу заострить внимание читателей на потерях в музыке при
прослушивании звукозаписи через два громкоговорителя, причем вне зависимости от
того, является ли она стереофонической или монофонической. Ничего неожиданного
здесь нет, если вспомнить, что для ясного восприятия слушателем музыки решающее
значение имеет точная передача в оба уха первой
волны звука. Первая волна звука сначала мобилизует внимание слушателя, а
затем включает торможение восприятия, в результате чего в следующий период порядка
30 мс ощущение слуховых объектов будет подавлено. Описанные явления получили
название "эффекта Хааса" [18]).
Первая волна звука выполняет свою роль меньше чем за 1,5 мс, поэтому
ранние отражения в помещении, обязанные своим появлением этой волне, из-за
своего неизбежного запаздывания не успевают ее исказить или видоизменить.
Получается, что первая волна звука (разумеется, только в естественных условиях
слушания) всегда приходит не от двух-, а от одноточечного источника, а значит,
формирует когерентные ушные сигналы. Некогерентные оставляющие, обусловленные,
например, остаточной от предшествующего сигнала реверберацией, выпадают из
внимания слушателя, так как оказываются в зоне либо упомянутого выше
торможения, либо действия бинауральной маскировки.
Эволюция органа слуха человека и
животных распорядилась так, что когерентность ушных сигналов, полученных от
первой волны звука, в дополнение к ее пусковому действию усиливает внимание
слушателя на начале каждого звука и на зонах их членения[8]. Нетрудно догадаться, что усиление
внимания слушателя именно к этим зонам на уровне субъективных ощущений должно
проявиться как дополнительное прояснение
структуры звучания.
Теперь вернемся к аудиосистеме с
двумя разнесенными громкоговорителями. "Все самое лучшее" о ней уже
сказано, а именно: из- за перекрестных сигналов и фазовых различий каналов она
ни в какой момент времени принципиально не способна передать ушам слушателя
когерентные сигналы, соответствующие фантомным источникам звука. А это, как я
писал выше, значит, что их бинаурального освобождения от маскировки практически
не происходит. Аудиосистема с одним громкоговорителем (то есть являющаяся
точечным источником), наоборот, всегда производит когерентные ушные сигналы,
однако без необходимых для освобождения от маскировки различий относительных
запаздываний, например соответствующих распределению источников звука на сцене
студии записи. Иными словами, стереофоническое звучание должно в меньшей
степени акцентировать внимание слушателя на структуре музыкальных звуков,
несмотря на то что и стереофоническое и монофоническое звучания обеспечивают
почти одинаковый нулевой эффект
освобождения от маскировки. Именно этим я объясняю наблюдаемый в эксперименте
(см. таблицу) субъективный прирост ясности,
динамики и энергичности при
одноканальном прослушивании по сравнению с двухканальным. По рассмотренным
причинам стереозвучание приходится воспринимать не как естественное, а как противоестественное.
И еще: в неидеальных акустических условиях, например в обычной жилой
комнате, моносистема всегда выиграет у стереосистемы по ясности звучания. Это
преимущество вызвано более выраженным, чем при стереофоническом
воспроизведении, эффектом освобождения "мономузыки" от маскировки
отражениями в помещении. Улучшенный эффект освобождения объясняется все тем же:
монофоническая система формирует когерентные ушные сигналы. В связи с этим
возникает вопрос, почему специалисты по озвучиванию концертных площадок
стараются как можно дальше друг от друга рассредоточить громкоговорители на
сцене и в зале, то есть сделать их звучание для слушателя менее когерентным.
Лично меня, уже три месяца назад
осуществившего переход на монофоническое звучание, плохая акустика комнаты
прослушивания перестала беспокоить.
В одной из следующих статей я
подробно остановлюсь на том, какие особенности конструкции должна иметь
монофоническая аудиосистема, где в комнате лучше расположить громкоговоритель,
а также расскажу о моей новой привязанности - низкочастотном громкоговорителе
фирмы "Klangfilm" (Германия, 1940-е годы) – см. фото 1.

Результаты сравнения звучания
Таблица
|
Признаки звучания |
Стереозаписи |
Монозаписи |
|||||||
|
А-В мк.техн. |
Поли-мк. техн. |
На 331/3 об/мин |
На 78 об/мин |
||||||
|
Воспроизведение |
|||||||||
|
2-канальное |
1-канальное |
2-канальное |
1-канальное |
2-канальное |
1-канальное |
2-канальное |
1-канальное |
||
|
Тональный баланс |
|
|
|
|
|||||
|
Тональная чистота |
|
|
|
|
|||||
|
Пространственное впечатление |
|
|
|
|
|||||
|
Ясность |
Разборчивость |
|
|
|
|
||||
|
Разделение голосов |
|
|
|
|
|||||
|
Детальность |
|
|
|
|
|||||
|
Характер звукоизвлечения |
|
|
|
|
|||||
|
Передача интонации |
|
|
|
|
|||||
|
Раздельность-связанность звуков |
|
|
|
|
|||||
|
Динамические контрасты |
|
|
|
|
|||||
|
Динамические
оттенки |
|
|
|
|
|||||
|
Натуральность тембров |
|
|
|
|
|||||
|
Индивидуальность тембров |
|
|
|
|
|||||
|
Красота тембров |
|
|
|
|
|||||
|
Энергичность |
|
|
|
|
|||||
|
Полнота передачи эмоций |
|
|
|
|
|||||
|
Точность передачи эмоций |
|
|
|
|
|||||
|
Целесообразность всех элементов звучания |
|
|
|
|
|||||
|
Связанность всех элементов звучания |
|
|
|
|
|||||
Обозначения: ![]() - лучше,
- лучше, ![]() - несколько лучше,
- несколько лучше, ![]() - едва
заметно лучше,
- едва
заметно лучше, ![]() - одинаково
- одинаково
Статья поступила 1 апреля 2001
Список литературы
1. Sakuma S. Audio Technology MJ Musen to Jikken, October, 1985.
2. Лихницкий А. Качество звучания. Новый подход к тестированию
аудиоаппаратуры. СПб. 1998, с. 51-67.
3. Блауэрт Й. Пространственный слух. М.,1979,с. 119.
4. Слуховая система /Ред. Я. А.
Альтман. Л., 1990, с. 380-383.
5.
Ebata M., Sone T., Nimura T.
Improvement of hearing ability by directional information. J. Acoust. Soc.
Amer., 43. 1968, рр.268-297.
6.
Cherry E.C. Some experiments on the
recognition of speech with one and with two ears, J. Acoust. Soc. Amer., 25.
1953, рр.975-979.
7.
Блауэрт Й. Ук. соч., с. 183.
8.
CherryE. C., Sayers B. McA.
"Human – Crosscorrelator" – A technique for measuring certain
parameters of speech perception, J. Acoust. Soc. Amer., 28.
1956, рр.
889-895.
9. Lehnhardt E. Die akustische Korrelation.
Arch. Ohren-Nasen-Kehlkopfheilk, 178. 1961, рр.493-497.
10. Ланге Ф. Корреляционная электроника. 1963, с. 339-345.
11. Блауэрт Й. Ук. соч., с. 176.
12. Блауэрт Й. Ук. соч., с. 173.
13.
Osman E. A correlation model of
binaural masking level differences, J. Acoust.Soc.Amer., 50. 1971, рр. 1494-1511.
14.
Блауэрт Й. Ук. Соч., с. 161-164.
15.
Schroeder M. R., Atal B. S. Computer
simulation of sound transmission in rooms, IEEE Conv. Rec., pt. 7. 1963, рр. 150-155.
16. Damaske P., Mellert V. Zur
richtungstreuen stereophonen Zweikanalubertragung, Acustica, 24. 1971,
рр.
222-225.
17.
Kйrer R., Plenge G., Wilkens H.
Correct spatial sound perception rendered by a spatial 2-channel recording
method, 37th AES Conv., H 3. 1969, New York.
18. Haas H. Uber den Einfluss eines
Einfachechos auf die Horsamkeit von Sprache, Acustica, 1. 1951, рр. 49-58.